In last week’s article we tried to understand exactly what Serverless technologies are, and what their pros and cons are in different IT infrastructure contexts.
An article series by: Sunil Kumar
Cloud Solutions Director – UK | Thought Leader
You can reach Sunil on LinkedIn here
Click here to read the first part of the article series.
Click here to read the third part of the article series.
To help you better understand whether Serverless is for you or not, let’s now have a look at the serverless tech stack and some of the most frequent use cases for serverless computing.
Overview of the Serverless Stack
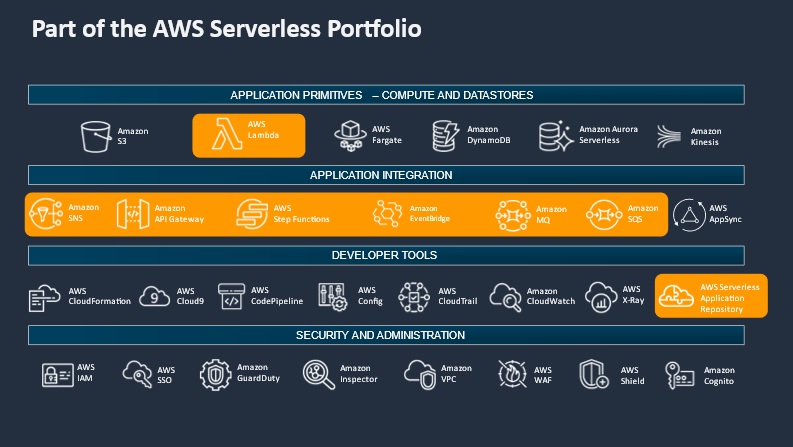
Here’s an overview of the services that usually make up the serverless stack:
Compute
These are the core elements that process and translate business logic from the code/software into outputs. Think of these as the good old CPU (Central Processing Units) minus the memory or the RAM element. Compute on cloud are ephemeral services, meaning the data input and output are not stored by the compute element. Examples include AWS Lambda, Fargate, Step Function, and others.
Databases
Storage or databases complement the compute elements – they help data to persist within the Cloud environment for use and reuse. E.g. DynamoDB, S3 buckets, etc.
Integration services
Connecting various parts of the micro-services architecture, integration services help glue individual components of the cloud system into one comprehensive whole. E.g. Event Bridge, API gateway, etc.
Developer tools
Various developer tools help not only with integration, but also with the deployment of the solution. Others, such as Application Repository, Cloud Formation, or Cloud Trail, help with storing the code, deploying the code and monitoring the access to the code. There are many other developer tools that combine to form Continuous Integration / Continuous Deployment (CI/CD), which I am sure you’ve come across before.
Security elements
The overarching umbrella that secures the solution. Examples include AWS WAF, AWS Shield, and so forth.
We will be doing a deep dive into each layer of the stack, and I will walk you through the nuances of the constituent elements in a future article, so stay tuned.
Is serverless for you?
Serverless finds its application in a wide variety of use cases, including batch processing, stream processing, web applications, mobile applications, IoT (Internet of Things), ETL (extract-transform-load) and more. Here are some frequent ones that you may have also come across:
Web and Mobile Applications
A common use cases for serverless is building backend APIs that service web and mobile applications. Serverless APIs are relatively simple to build and manage, and work well in fluctuating load conditions.
Stream and batch processing
Serverless is a well-suited architecture for event-driven data processing. Lambda functions can be assigned to consume events from data streams, or they can be set as workers to process tasks in bulk, which is why the pay-per-use billing model is attractive. Although bear in mind that at high loads, compute can be more expensive with serverless.
Internet of Things (IOT)
Services like Alexa and home appliances like iRobot are well-known serverless users. Devices that connect to internet to read or write data are good use cases for serverless architecture. Serverless is also seeing a lot of adoption in home automation and other custom-built solutions.
Cloud Automation and CRON jobs
Serverless is well suited for automating cloud tasks such as backing up databases, changing configurations periodically, or for taking care of periodical jobs that don’t require the computing power of a dedicated server.
In the upcoming weeks, we will be sinking our teeth deeper into the constituent elements of serverless. We will be taking a closer look at the individual layers that make up the serverless stack and how best to use them to achieve your organization’s goals, so subscribe to our blog and follow us on social media to be the first to know when the articles are published.
Read the full article series:
The benefits and drawbacks of Serverless technologies
Nuts and bolts of Serverless technologies – part I | R Systems