Picking up from where we left in our previous article, let’s dive deeper into the nitty-gritty of serverless technologies.
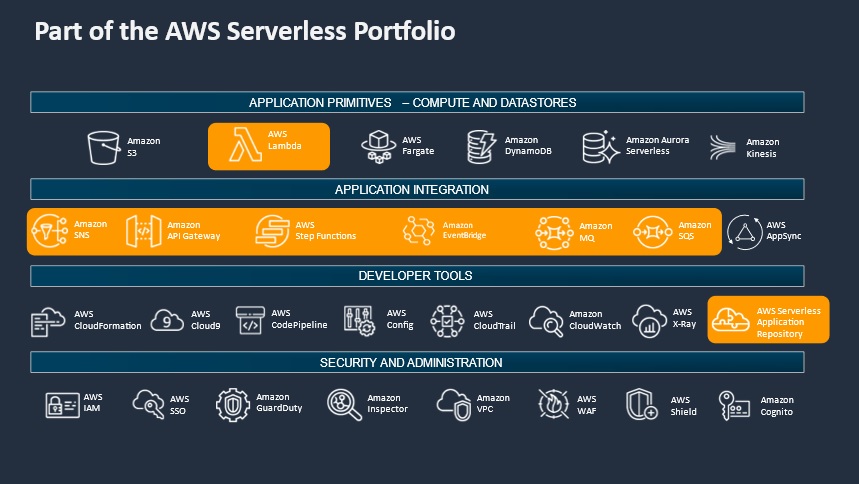
There are seven areas you should consider when designing or building a serverless applications workloads.
- Compute Layer: It contains the runtime environment on which business logic is deployed and executed. Compute layer interfaces with external systems and controls access and authorization to and from these runtimes. Here are some of the services that make up the compute layer:
a. AWS Lambda:

- In simple terms – Lambda is a compute service that lets you run code without provisioning or managing servers. Lambda runs your code on a high-availability compute infrastructure and performs all the administration of the compute resources, including server and operating system maintenance, capacity provisioning and automatic scaling, code monitoring, and logging.
With Lambda, you can run code for virtually any type of application or backend service. Lambda supports a wide variety of programming languages through the use of runtimes such as Java, .Net, Python, Ruby, Go, Node.JS, etc.
All you need to do is supply your code in one of the languages that Lambda supports.
Lambda is suitable for running stateless serverless applications on a managed platform that supports microservices architectures, deployment, and management of execution at the function layer.b. AWS Fargate:
- AWS Fargate is a serverless, pay-as-you-go compute engine technology that you can use with Amazon ECS to run containers without having to manage servers or clusters of Amazon EC2s. With Fargate, you no longer have to provision, configure, or scale clusters of virtual machines to run containers.
This removes major infrastructure decision overheads including the need to choose server types, decide when to scale your clusters or optimize cluster packing.
When you run your Amazon ECS tasks and services with the Fargate launch type or a Fargate capacity provider, you package your application in containers, specify the Operating System, CPU, and memory requirements, define networking and IAM policies, and launch the application.
Each Fargate task has its own isolation boundary and does not share the underlying kernel, CPU resources, memory resources, or elastic network interface with another task.
Fargate helps you build and deploy applications, APIs, and microservices architectures with the speed and immutability of containers.
2. Data Layer – the above two services, i.e. AWS Lambda and AWS Fargate are examples of services that are typical of the components that make up the Compute layer, the following two, i.e. Amazon S3 and Amazon DynamoDB make up the Data layer components.
Whilst the data that transact through a compute layer such as AWS Lambda is held in the ephemeral storage, the need to hold processed data in a persistent storage location is solved by including components from the Storage layer.
a. Amazon S3:
One of the oldest AWS services, S3 is an object store in its simplest form. The object that you store on S3 can be anything, from txt files to video files to log files to binaries. It provides a highly available key-value store that complements the impersistent storage types of the computing layer.
With Amazon S3 you can build fast, powerful mobile and web-based cloud-native applications that are highly available and scalable. It provides a secure shared environment to support modern microservices delivery.
b. DynamoDB:
- AWS Fargate is a serverless, pay-as-you-go compute engine technology that you can use with Amazon ECS to run containers without having to manage servers or clusters of Amazon EC2s. With Fargate, you no longer have to provision, configure, or scale clusters of virtual machines to run containers.

-
-
-
- It is a managed NoSQL database for persistent storage. With DynamoDB, you can create database tables that can store and retrieve any amount of data and serve any level of request traffic. It allows to scale up or scale down tables’ throughput capacity without downtime or performance degradation.
-
-
3. Streaming Layer: This layer is mainly concerned with data ingestion into the compute layer. It manages real-time analysis and processing of streaming data. AWS messaging services enable different software systems and end devices–often using different programming languages, and on different platforms–to communicate and exchange information.
- a. Amazon Kinesis can be used to collect, process, and analyse real-time, streaming data to gain timely insights and react quickly to new information. Amazon Kinesis comes in different variants – With Amazon Kinesis Data Analytics, you can run standard SQL or build entire streaming applications using SQL.

- b. Amazon Kinesis Firehose captures, transforms, and loads streaming data into Kinesis Data Analytics, Amazon S3, Amazon Redshift, and OpenSearch Service, enabling near real-time analytics with existing business intelligence tools.
In the next article, we will be looking into the details of the next four layers, i.e., the application integration layer, the user management and identity layer, the edge layer, and the systems monitoring and deployment layer.
Read the first two articles of this series:
The benefits and drawbacks of Serverless technologies
Are Serverless technologies a good fit for your organization?